CEP001 - CoLRev Framework
Author |
Gerit Wagner, Julian Prester |
Status |
Draft |
Created |
2022-09-01 |
Discussion |
TODO : link-to-issue |
License |
Creative Commons Attribution-NonCommercial-NoDerivs 3.0 License |
Table of contents
Abstract
The Collaborative Literature Reviews (CoLRev) framework provides a standardized environment, an extensible core, and a reference implementation for conducting highly collaborative reviews with a team of researchers and state-of-the-art algorithms.
Definitions:
A literature review is a collaborative process involving researcher-crowd-machine ensembles, which takes records (search results in the form of metadata) and full-text documents as qualitative, semi-structured input to develop a synthesis. The result can take different forms, including codified standalone review papers, published web repositories, or a locally curated living reviews.
Guiding principles:
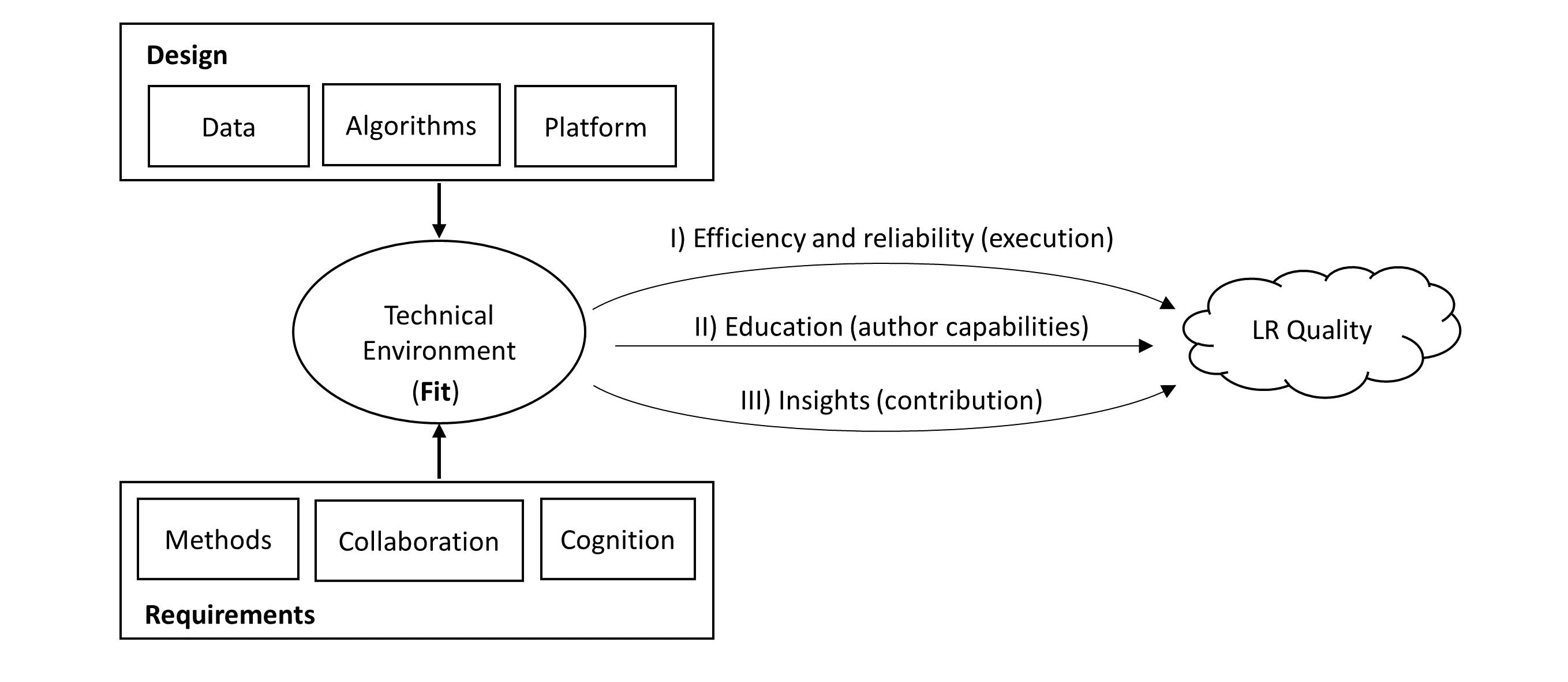
Fit: adaptability/configurability: research goals, type of review, methodological coherence, disciplines, expertise of users - design for humans/self-explanatory
Rigor: selection and improvement of the best algorithms, transparency of changes, suggesting rigorous defaults, reporting is at the discretion of users
Openness: related to data, software and users - especially design for reuse of curated data, of the best algorithms, of prior reviews (each project should enable the broadest extent of reuse scenarios, ideally even those that were not anticipated at the time of publication)
1. Area: Methods
1.1 Framework for (reproducible) research
Established frameworks for reproducible research using Git do not apply to literature reviews:
Dynamics: Common notions of raw/immutable input data do not apply. In literature reviews, data and interpretations evolve dynamically throughout the process.
Non-determinism: Common notions of deterministic computational processing operations do not apply. In literature reviews, processing operations are often manual, rely on external (changing) data sources and are inherently non-deterministic.
Atomicity: Common notions of processing the dataset as a whole are insufficient, i.e., the in-memory-processing model, as exemplified by the tidyverse pipe operators, does not apply. In literature reviews, processing occurs on a per-paper basis, requiring validation and (potentially) corrections on a more granular level.
Structure: Common notions of data as structured lists-of-unique-observations do not apply. In literature reviews, search results (metadata) are retrieved redundantly from multiple sources (to compensate for imperfect coverage/errors in the retrieval procedures) and associations between structured metadata and semi-structured full-text documents can form complex, layered graphs.
1.3 Systematicity and transparency
The design of tools can have a profound impact on the systematicity (internal rigor) and transparency (external rigor, as reported) of literature reviews.
Per default, tools should encourage high levels of systematicity (internal rigor) and provide functionality that efficiently supports systematic review practices.
It should be at the users discretion to choose higher or lower degrees of systematicity. This is particularly relevant if systematicity requires additional manual efforts that may not be in line with the goals and nature of the review.
Note: When presenting a literature review, “qualitative systematic reviews” (as a very particular type of review) should be distinguished from general notions of literature reviews (that are conducted in a systematic manner). Every review varies on a scale of systematicity and transparency .
1.4 Typological pluralism
The methodological literature increasingly emphasizes typological pluralism, referring important differences between types of reviews, such as qualitative systematic reviews, theory development reviews, scoping reviews, or meta-analyses. As a result, a key question is how literature review technology should differ depending on the type of review. The main propositions of CoLRev are:
The generic literature review process (search, prescreen, screen, synthesize with the corresponding record management steps) applies to all types of reviews.
The most substantial differences are found in the synthesis step, which involves different types of data (e.g., structured, unstructured), different forms of synthesis (e.g., narrative, statistical) and subtasks (e.g., quality appraisal, meta-analysis, manuscript development).
In the other processes, differences between review types manifest in different parameters.
As an implication, tools should be designed to synergize in all operations that precede the synthesis and provide flexibility for different forms of synthesis that are in line with the respective type of review.
2. Area: Design
2.1 Architecture
The architecture of CoLRev is divided into three packages:
The CoLRev environment, colrev, operates standardized data structures and a process model on top of Git repositories. It also offers an extensible reference implementation covering all process steps of the review process.
The CoLRev hooks, colrev_hooks (i.e., custom Git pre-commit hooks) check conformance with the standardized structures before a new version of the project (Git commit) is created.
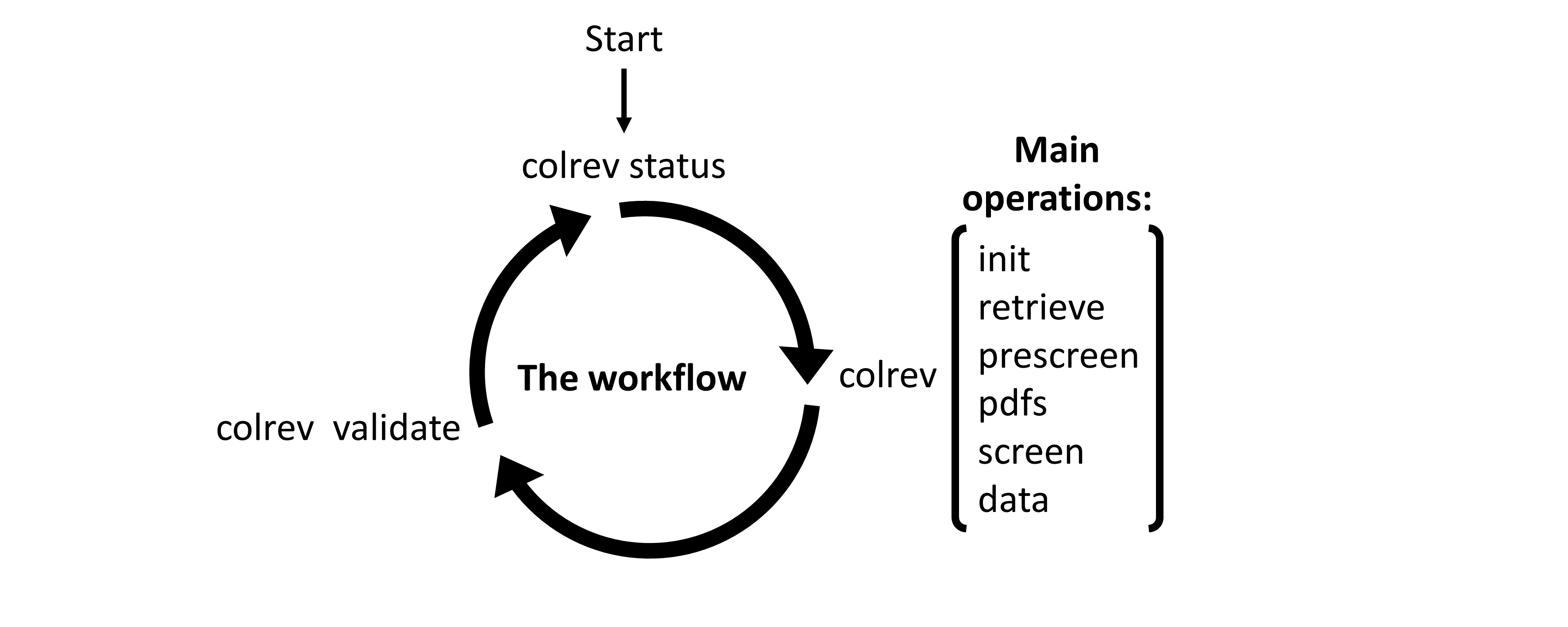
The CoLRev command line interface, colrev (cli), provides access to the processing operations and additional features. Complexity is hidden behind the three-step workflow and the
colrev statuscommand that provides instructions based on the context of the project.
The extensible part of colrev adopts batteries included but swappable as a principle to reconcile the need for an efficient end-to-end process with the possibility to select and combine specific tools. Users can – for each step of the review process – rely on the powerful reference implementation of CoLRev or select custom tools.
2.2 Git for literature reviews
The CoLRev environment tightly integrates with the transparent collaboration model of Git for the entire review process. A key lessons from the tidyverse (R) is that a shared philosophy of the data is instrumental for collaboration, as well as the application and development of functionality provided by complementary packages. The design is based on the following versioning and collaboration principles:
As a foundation, Git provides the full flexibility of distributed workflow setups.
CoLRev serves as the database management system (or “workflow engine”) that takes care of data consistency, operates a shared model of the review steps, and thereby enables collaboration. This is a missing element in current Git-based literature reviews.
It should always be possible to edit the data directly. Before creating a commit, the validation and formatting of changes is automatically triggered by the pre-commit hooks. This built-in feature makes CoLRev projects fault-tolerant and facilitates collaboration through Git.
Commits should be atomic. A commit corresponds to an individual operation, which facilitates validation efforts. Commits and pushes/pulls should be frequent to avoid merge conflicts.
CoLRev uses Git to facilitate collaboration between researchers and machines. As such, all operations should be prepared to be called by humans or machines. For example, the search could be updated manually or by a Github action. This does not mean that all steps should be completed automatically. For example, if the setup requires manual screening, machines should be able to call the screen operation, but it should not lead to record state transitions.
Notes:
Git is used most effectively for line-based versioning of text-files. Visualizing changes is more demanding for structured data (csv) and impossible for binaries (e.g., Word documents).
Versions are accompanied by a commit report, which provides a quick overview of the status.
2.3 Data structures and provenance
The CoLRev framework is based on an opinionated and scientifically grounded selection of data structures, file-paths and operating principles. Ideally, constraining the set of possible data formatting and storage options improves workflow efficiency (because tools and researchers share the same philosophy of data), freeing time and mental energy for literature analysis and synthesis.
The main goal of data structuring is to give users a transparent overview of (1) the detailed changes that were made, (2) by whom, and (3) why. To accomplish these goals, CoLRev tracks a colrev_status for each record (see the :ref.`model <operations>`):
The colrev_status is used to determine the current state of the review project.
It is used by the ReviewManager to determine which operations are valid according to the order of operations (e.g., records must be prepared before they are considered for duplicate removal, PDFs have to be acquired before the main inclusion screen).
Tracking the colrev_status` enables incremental duplicate detection (record pairs that have passed deduplication once do not need to be checked again in the next iterations).
Strictly adhering to the state machine allows us to rely on a simple data structure (e.g., colrev_status=”synthesized”` implies pdf_prepared, md_prepared, rev_included, rev_prescreen_included).
An underlying assumption is that different types of reviews share the same process model (with different parameters) and that the main differences are in the data extraction and analysis stages (e.g., requiring structured or unstructured data formats).
The data structures distinguish raw data sources (stored in data/search/) and the main records (stored in data/records.bib).
Raw data sources:
Raw data sources represent the latest version of the records retrieved from source, i.e., they can be updated by API-based sources. Manual edits should be applied to the main records (data/records.bib).
Main records:
The file contains all records.
It is considered the single version of truth with a corresponding version history.
Records are sorted according to IDs, which makes it easy to examine deduplication decisions. Once propagated to the review process (the prescreen), the ID field (e.g., BaranBerkowicz2021) is considered immutable and used to identify the record throughout the review process.
To facilitate an efficient visual analysis of deduplication decisions (and preparation changes), CoLRev attempts to set the final IDs (based on formatted and completed metadata) when importing records into the main records file (IDs may be updated until the deduplication step if the author and year fields change).
For main records, ID formats such as three-author+year (automatically generated by CoLRev), are recommended because:
Semantic IDs are easier to remember compared to arbitrary ones like DOIs or numbers that are incremented.
Global identifiers (like DOIs or Web of Science accession numbers) are not available for every record (such as conference papers, books, or unpublished reports).
Shorter formats (like first-author+year) may often require arbitrary suffixes.
Individual records in the main records are augmented with:
The colrev_status field to track the current state of each record in the review process and to facilitate efficient analyses of changes (without jumping between the main records file and a screening sheet, data sheet, and manuscript).
The colrev_origin field to enable traceability and analyses (in both directions).
For the main records and the converted raw data, the BibTeX is selected for the following reasons:
BiBTeX is a quasi-standard format that is supported by most reference managers and literature review tools (overview).
BibTeX is easier for humans to analyze in Git-diffs because field names are not abbreviated (this is not the case for Endnote .enl or .ris formats), it is line-based (tabular, column-based formats like csv are hard to analyze in Git diffs), and it contains less syntactic markup that makes it difficult to read (e.g., XML or MODS).
BibTeX is easy to edit manually (in contrast to JSON) and does not force users to prepare the whole dataset at a very granular level (like CSL-JSON/YAML, which requires each author name to be split into the first, middle, and last name).
BibTeX can be augmented (including additional fields for the colrev_origin, colrev_status, etc.).
BibTeX is more flexible (allowing for new record types to be defined) compared to structured formats (e.g., SQL).
[Overview of bibliographic data formats](https://format.gbv.de/).
2.4 State-of-the-art algorithms
The goal of CoLRev is to build on the latest state-of-the-art algorithms and to incorporate the leading packages for the requisite functionality. This is important to achieve optimum performance across the whole process, to benefit from ongoing improvements in each subproject and to avoid duplicating efforts across projects. For long-term sustainability and in line with the guiding principles, only open source packages are considered.
Overview of packages and reasons for selection:
Git: the leading collaborative versioning environment with a broad academic userbase
Docker: one of the leading platforms for container-based microservices and supported by most of the relevant academic microservices (e.g., GROBID, Zotero, Opensearch)
GROBID: the leading bibliographic reference and citation parser
Zotero import translators: one of the most active projects for translating bibliographic reference formats
pybtex: the most actively developed pythonic BibTeX parser with high load performance
Tesseract/ocrmypdf: the leading (non-proprietary) OCR engine (machine-readability of PDF content)
dedupe: one of the leading python packages for record linkage, offering convenience functions supporting active learning, learnable similarity functions and blocking algorithms
Pandoc and CSL: the leading projects for creating scientific documents from markdown, the standard for Git-versioned manuscripts
Opensearch: the leading open source search engine and search dashboard
3. Area: Cognition
3.1 The user workflow model
Desigining a self-explanatory, fault-tolerant, and configurable user workflow - Simple, self-explanatory end-to-end user workflow (3 steps, 1 command: status) : suggesting next steps (hiding complexity), preventing errors, improving efficiency
In its basic form, the workflow consists of iteratively calling colrev status > colrev [process] > Git [process].
It is self-explanatory with colrev status recommending the next colrev [process] or Git [process].
3.2 Priority processing
Design processing operations in such a way that cognitive effort is saved and allocated effectively. Changes with similar degrees of confidence are bundled in commits (rounds) to facilitate prioritized validation e.g., prep-rounds, as review ordered screen or reading heuristics.
3.3 Validate-and-undo
To maintain high data quality, it is imperative to facilitate efficient validation and undoing of changes.
Validation and undoind of changes should be supported by every operation.
Algorithmic application of changes and (efficient) undo operations are preferred over manual entry/changes.
Reuse (curated content, across projects) should be facilitated to avoid redundant efforts.
4. Area: Community
4.2 Layered and multifaceted view
Ideally, CoLRev projects form highly connected networks with data flowing between individual repositories that focus metadata, content curation, broad topic reviews, and specific review papers. In some cases, it is useful to require data that is reconciled to a singular version of the truth, while in other cases, different philosophical and theoretical perspectives may better be represented by separate data layers.
Integration and data flows between project repositories, topic repositories, and curated metadata/data repositories should be supported.
Reconciliation of singular truths and the development of alternative interpretative layers should be supported.
4.3 Curation per default
Reuse of curated content should be the default (as easy as possible, expected by authors, journals, …).
Reuse of community-curated data is a built-in feature of CoLRev, aimed at saving efforts across projects as well as increasing accuracy and richness of the process. Per default, every CoLRev repository that is registered locally makes its data accessible to all other local repositories. This means that all general operations (e.g., preparing metadata or linking PDFs) are completed automatically once indexed. Of course, reuse is the most powerful when curated content (such as reviews, topic or journal-related repositories) is shared within teams or publicly.