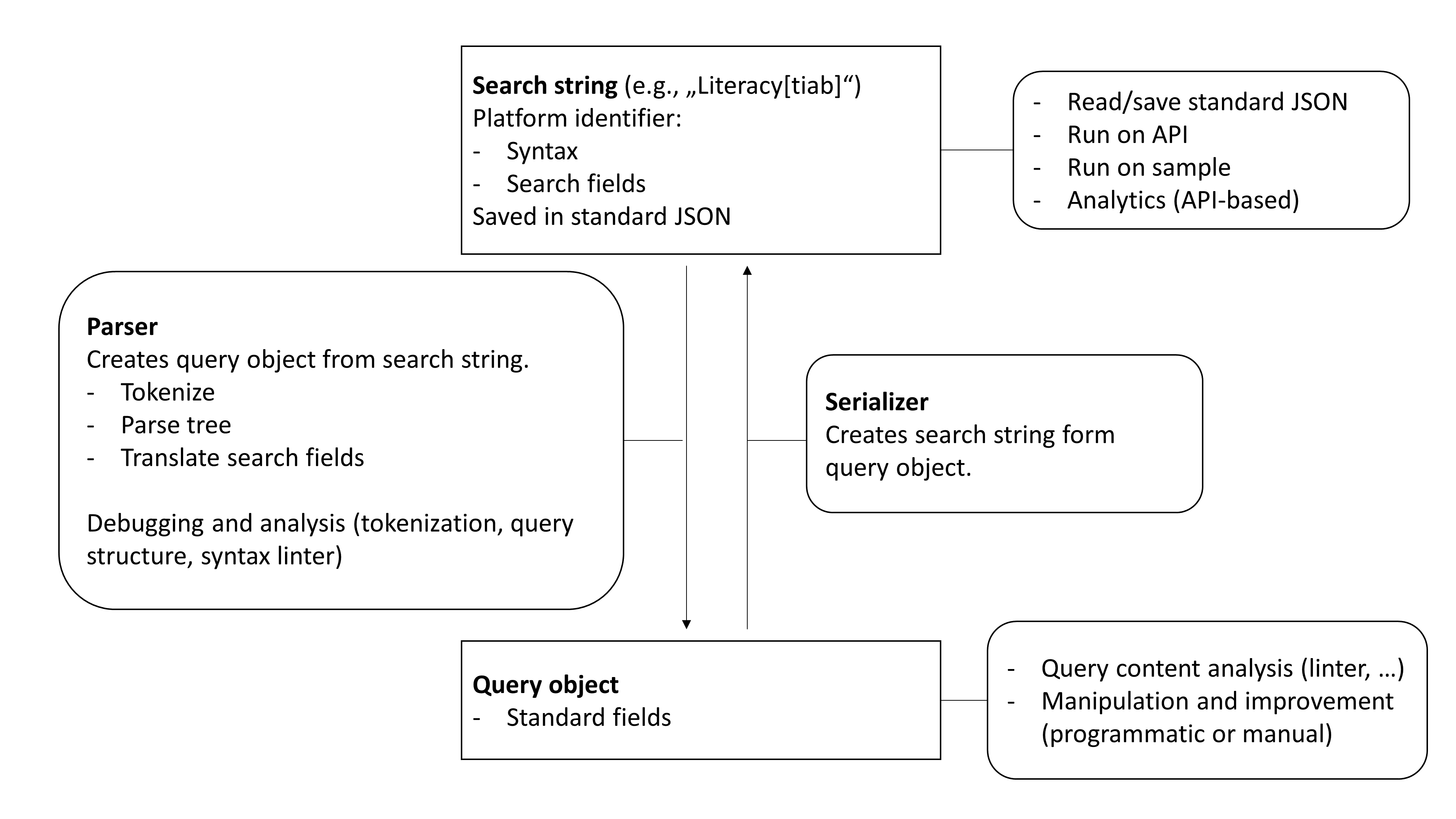
Developing a parser
Development setup
pip install -e ".[dev]"
Skeleton
A code skeleton is available for the parser and tests:
#!/usr/bin/env python3
"""XY query parser."""
from __future__ import annotations
import re
import typing
from search_query.constants import PLATFORM
from search_query.constants import PLATFORM_FIELD_TRANSLATION_MAP
from search_query.constants import QueryErrorCode
from search_query.constants import TokenTypes
from search_query.parser_base import QueryListParser
from search_query.parser_base import QueryStringParser
from search_query.query import Query
from search_query.query import SearchField
class XYParser(QueryStringParser):
"""Parser for XY queries."""
FIELD_TRANSLATION_MAP = PLATFORM_FIELD_TRANSLATION_MAP[PLATFORM.XY]
PARENTHESIS_REGEX = r"[\(\)]"
LOGIC_OPERATOR_REGEX = r"\b(AND|OR|NOT)\b"
SEARCH_FIELD_REGEX = r"..."
OPERATOR_REGEX = r"..."
# ...
pattern = "|".join(
[
SEARCH_FIELD_REGEX,
OPERATOR_REGEX,
# ...
]
)
OPERATOR_PRECEDENCE = {
# ...
}
def get_precedence(self, token: str) -> int:
"""Returns operator precedence for logical and proximity operators."""
# Change precedence or add operators
# Implement and override methods of parent class (as needed)
def tokenize(self) -> None:
"""Tokenize the query_str."""
# Parse tokens and positions based on regex pattern
for match in re.finditer(self.pattern, self.query_str):
token = match.group()
token = token.strip()
start, end = match.span()
# Determine token type
if re.fullmatch(self.PARENTHESIS_REGEX, token):
if token == "(":
token_type = TokenTypes.PARENTHESIS_OPEN
else:
token_type = TokenTypes.PARENTHESIS_CLOSED
elif re.fullmatch(self.LOGIC_OPERATOR_REGEX, token):
token_type = TokenTypes.LOGIC_OPERATOR
# ...
else:
self.add_linter_message(QueryErrorCode.TOKENIZING_FAILED, (start, end))
continue
self.tokens.append((token, token_type, (start, end)))
# Override methods of parent class (as needed)
def parse_query_tree(
self,
tokens: list,
search_field: typing.Optional[SearchField] = None,
) -> Query:
"""Parse a query from a list of tokens."""
# Parse a query tree from tokens (bottom-up or top-down)
# Add messages to self.linter_messages
# self.add_linter_message(QueryErrorCode.ADD_CODE, (start, end))
def translate_search_fields(self, query: Query) -> None:
"""Translate search fields."""
# Translate search fields to standard names using self.FIELD_TRANSLATION_MAP
# Add messages to self.linter_messages if needed
# self.add_linter_message(QueryErrorCode.ADD_CODE, (start, end))
def parse(self) -> Query:
"""Parse a query string."""
self.tokenize()
self.add_artificial_parentheses_for_operator_precedence()
query = self.parse_query_tree(self.tokens)
self.translate_search_fields(query)
# If self.mode == "strict", raise exception if self.linter_messages is not empty
return query
class XYListParser(QueryListParser):
"""Parser for XY (list format) queries."""
LIST_ITEM_REGEX = r"..."
def __init__(self, query_list: str) -> None:
super().__init__(query_list, XYParser)
def get_token_str(self, token_nr: str) -> str:
return f"#{token_nr}"
# Override methods of parent class (as needed)
# The parse() method of QueryListParser is called to parse the list of queries
#!/usr/bin/env python
"""Tests for search query translation"""
import json
from pathlib import Path
import pytest
from search_query.parser_base import QueryStringParser
from search_query.parser_xy import XYParser
from search_query.query import Query
# flake8: noqa: E501
# to run (from top-level dir): pytest tests/test_parser_xy.py
@pytest.mark.parametrize(
"query_string, tokens",
[
(
"AB=(Health)",
[("AB=", (0, 3)), ("(", (3, 4)), ("Health", (4, 10)), (")", (10, 11))],
),
],
)
def test_tokenization_xy(query_string: str, tokens: tuple) -> None:
xyparser = XYParser(query_string)
xyparser.tokenize()
assert xyparser.tokens == tokens, print_debug_tokens(xyparser, tokens, query_string)
def print_debug_tokens(
xyparser: QueryStringParser, tokens: tuple, query_string
) -> None:
print(query_string)
print()
print(xyparser.tokens)
print(xyparser.get_token_types(xyparser.tokens, legend=True))
print(tokens)
directory_path = Path("data/xy")
file_list = list(directory_path.glob("*.json"))
# Use the list of files with pytest.mark.parametrize
@pytest.mark.parametrize("file_path", file_list)
def test_xy_query_parser(file_path: str) -> None:
"""Test the translation of a search query to a xy query"""
with open(file_path) as file:
data = json.load(file)
query_string = data["search_string"]
expected = data["parsed"]["search"]
parser = XYParser(query_string)
query = parser.parse()
query_str = query.to_string()
assert query_str == expected, print_debug( # type: ignore
parser, query, query_string, query_str
)
def print_debug(
parser: QueryStringParser, query: Query, query_string: str, query_str: str
) -> None:
print(query_string)
print()
print(parser.get_token_types(parser.tokens))
print(query_str)
print(query.to_string("structured"))
@pytest.mark.parametrize(
"query_string, linter_messages",
[
(
"AB-(Health)",
[],
),
],
)
def test_linter_xy(query_string: str, linter_messages: tuple) -> None:
xyparser = XYParser(query_string)
try:
xyparser.parse()
except Exception:
pass
assert xyparser.linter_messages == linter_messages
To parse a list format, the numbered sub-queries should be replaced to create a search string, which can be parsed with the standard string-parser. This helps to avoid redundant implementation.
Tokenization
Translate search fields: Mapping Fields to Standard-Fields
The search fields supported by the database (Platform-Fields) may not necessarily match exactly with the standard fields (Standard-Fields) in constants.Fields.
We distinguish the following cases:
1:1 matches
Cases where a 1:1 match exists between DB-Fields and Standard-Fields are added to the constants.SYNTAX_FIELD_MAP.
1:n matches
Cases where a DB-Field combines multiple Standard-Fields are added to the constants.SYNTAX_COMBINED_FIELDS_MAP. For example, Pubmed offers a search for [tiab], which combines Fields.TITLE and Fields.ABSTRACT.
When parsing combined DB-Fields, the standard syntax should consist of n nodes, each with the same search term and an atomic Standard-Field. For example, Literacy[tiab] should become (Literacy[ti] OR Literacy[ab]). When serializing a database string, it is recommended to combine Standard-Fields into DB-Fields whenever possible.
n:1 matches
If multiple Database-Fields correspond to the same Standard-Field, a combination of the default Database-Field and Standard-Field are added to the constants.SYNTAX_FIELD_MAP. Non-default Database-Fields are replaced by the parser. For example, the default for MeSH terms at Pubmed is [mh], but the parser also supports [mesh].
Search Field Validation in Strict vs. Non-Strict Modes
Search-Field required |
Search String |
Search-Field |
Mode: Strict |
Mode: Non-Strict |
|---|---|---|---|---|
Yes |
With Search-Field |
Empty |
ok |
ok |
Yes |
With Search-Field |
Equal to Search-String |
ok - search-field-redundant |
ok |
Yes |
With Search-Field |
Different from Search-String |
error: search-field-contradiction |
ok - search-field-contradiction. Parser uses Search-String per default |
Yes |
Without Search-Field |
Empty |
error: search-field-missing |
ok - search-field-missing. Parser adds title as the default |
Yes |
Without Search-Field |
Given |
ok - search-field-extracted |
ok |
No |
With Search-Field |
Empty |
ok |
ok |
No |
With Search-Field |
Equal to Search-String |
ok - search-field-redundant |
ok |
No |
With Search-Field |
Different from Search-String |
error: search-field-contradiction |
ok - search-field-contradiction. Parser uses Search-String per default |
No |
Without Search-Field |
Empty |
ok - search-field-not-specified |
ok - Parser uses default of database |
No |
Without Search-Field |
Given |
ok - search-field-extracted |
ok |
Tests
All test data should be stored in standard JSON.